
…
The post Data Annotation in Healthcare AI: Key Challenges, Risks, and Best Practices appeared first on The Total Entrepreneurs.

What happens when a mislabeled scan, note, or lab value becomes part of a healthcare AI model’s training data?
In healthcare, annotation errors are not just technical defects. They influence how AI systems interpret disease, urgency, treatment context, and patient risk. That makes healthcare AI annotation far more demanding than standard data labeling.
Clinical ambiguity, inconsistent multimodal data, delayed ground truth, and hidden bias all make medical data annotation difficult to standardize. At the same time, HIPAA compliance, access controls, audit trails, and secure workflows cannot be treated as final checks.
This blog explains why healthcare AI annotation carries a higher risk, where annotation workflows often fail, which best practices help improve label quality, and how data annotation services help.
Why Data Annotation in Healthcare Carries a Higher Risk
Healthcare models learn from data that reflects clinical decisions, documentation habits, imaging protocols, care access, and patient demographics. Each label can influence how a model interprets disease, severity, urgency, or treatment context.
That makes annotation quality a clinical risk factor.
The FDA maintains a public list of AI-enabled medical devices authorized for marketing in the United States. The agency notes that these devices have met applicable premarket requirements, including review of safety, effectiveness, intended use, and technological characteristics.
Troy Tazbaz, director of the Digital Health Center of Excellence at the FDA’s Center for Devices and Radiological Health, noted that AI/ML health products pose unique considerations due to their complexity and iterative, data-driven development. This matters for healthcare annotation because labeled datasets influence how these systems are trained, evaluated, and updated.
Core Challenges of Data Annotation in Healthcare AI
- Clinical Ambiguity Is Often Built Into the Source Data
Clinical data rarely present a single obvious label. A radiology finding may be subtle. A pathology slide may contain borderline regions. A physician’s note may describe a suspected diagnosis, not a confirmed one.
That creates disagreement among qualified reviewers.
For example, two radiologists may mark different tumor margins on the same MRI. Both annotations may be clinically defensible. A simple majority-vote workflow can flatten that nuance and train the model on false certainty.
A stronger annotation workflow should separate:
- Clinical Evidence: What is visible or documented in the source data.
- Target Label: How that evidence maps to the project’s reference standard.
- Label Uncertainty: How confident reviewers are in the assigned label.
This is where medical data annotation requires adjudication rules, not only annotation tools.
- Healthcare Data Is Multimodal and Inconsistent
Healthcare AI projects often combine imaging, EHR text, lab results, pathology slides, waveforms, claims, and device data. Each source follows different structures and quality constraints.
Medical imaging may rely on DICOM metadata. Clinical notes may contain abbreviations, misspellings, and free-text identifiers. Lab data may use LOINC codes. Diagnoses may use ICD-10-CM or SNOMED CT.
The healthcare data annotation schema must account for those differences before labeling begins. Otherwise, the same clinical concept appears under multiple labels across systems.
- Ground Truth Can Be Delayed or Unavailable
In healthcare, the correct answer may only become clear later.
A sepsis model may need labels based on downstream clinical outcomes. A cancer detection model may require biopsy confirmation. A readmission-risk model may depend on events outside the originating health system.
Weak ground-truth design creates misleading labels. The model may learn from documentation rather than from clinical reality.
A practical annotation plan should define:
- The acceptable evidence source for each label
- The time window for outcome confirmation
- The reviewer’s role authorized to resolve uncertainty
- The audit trail for changed labels
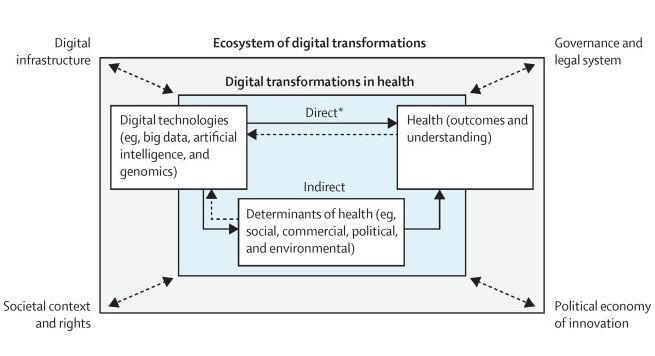
- Bias Enters Through Data Composition and Labeling Rules
Bias is not limited to model architecture. It can enter through who appears in the dataset, how often conditions are tested, and how clinical findings are documented.
The Lancet Digital Health’s STANDING Together recommendations warn that bias in health datasets can perpetuate health inequalities at scale. The recommendations emphasize transparent dataset documentation and proactive evaluation across population groups.
Source: The Lancet
This has direct implications for AI training data for healthcare. Annotation teams need visibility into the distribution of demographics, care settings, modality types, device manufacturers, and acquisition protocols.
A model trained on narrow labels may perform well in retrospective testing and fail in a different hospital network.
The Challenge: HIPAA Compliance in Data Annotation Workflow
Healthcare annotation programs often fail when compliance is treated as a final checklist. Privacy, access control, contracting, and data retention need to shape the workflow before data enters the labeling environment.
HIPAA Controls Must Cover the Annotation Workflow
When healthcare data contains identifiable patient information, HIPAA requirements govern how that data is accessed, used, shared, stored, and protected.
That makes HIPAA compliance in data annotation a workflow design issue. It affects data intake, annotator access, review queues, storage, exports, and deletion.
Minimum controls should include:
- Business associate agreements for vendors handling PHI
- Role-based access by project and data type
- De-identification before annotation where feasible
- Encryption in transit and at rest
- Audit logs for every access and export
- Prohibition of local downloads unless explicitly approved
- Documented retention and deletion schedules
HHS recognizes two de-identification methods under the HIPAA Privacy Rule: Expert Determination and Safe Harbor. It also notes that de-identified data still carries some re-identification risk.
That risk is higher in free-text notes. HHS specifically notes that clinical narratives can contain rich context that may identify a patient.
Security Risk Is Material, Not Administrative
IBM’s 2025 Cost of a Data Breach research reported an average healthcare breach cost of USD 7.42 million, the highest among industries for the 14th consecutive year.
That figure changes the economics of annotation outsourcing. A low-cost labeling model can become expensive when PHI access, weak audit controls, or unmanaged subcontracting creates exposure.
Best Practices for Reliable Healthcare AI Annotation
- Assign Experts to Clinically Complex Tasks
Clinical interpretation should be handled by qualified reviewers. General annotators can support structured tasks, but diagnostic, severity, and treatment-adjacent labels require medical expertise.
Use specialist review for:
- Radiology findings: Subtle abnormalities may need radiologist validation before classification.
- Pathology slides: Borderline tissue regions require expert review before labeling.
- Tumor segmentation: Boundaries must follow anatomical and clinical criteria.
- Disease severity grading: Labels must align with accepted clinical thresholds.
- Clinical notes: Negation, temporality, symptoms, and suspected diagnoses need contextual review.
- Rare conditions: Low-frequency findings require experienced reviewers to reduce missed labels.
- Keep Human Review in AI-Assisted Labeling
Pre-labeling tools can reduce manual effort, but final labels need reviewer control. Model-generated suggestions may repeat prior errors, miss rare findings, or overfit to source-data bias.
The workflow should allow reviewers to:
- Accept labels supported by clinical evidence.
- Correct incomplete or misplaced labels.
- Reject labels not supported by the record.
- Escalate borderline cases to senior reviewers.
- Update guidelines when recurring exceptions appear.
- Prioritize Label Quality Over Dataset Volume
Large datasets lose value when labels are noisy or weakly validated. Smaller datasets with confirmed labels often produce stronger model inputs.
Track quality through:
- Inter-rater agreement: Measures whether reviewers label the same case consistently.
- Label rejection rate: Shows how often labels fail quality review.
- Adjudication rate: Identifies cases requiring senior clinical resolution.
- Reviewer-level variance: Detects reviewers whose patterns differ from the accepted standard.
- Error rate by modality: Compares quality across imaging, EHR text, claims, and pathology.
- Error rate by label class: Highlights labels that are missed, confused, or overused.
- Use Medical-Grade Annotation Tools
Healthcare datasets need tools built for clinical formats, imaging precision, secure access, and review workflows. Generic platforms often lack these controls.
Key capabilities include:
- DICOM support for radiology and imaging workflows.
- NIfTI support for neuroimaging and volumetric datasets.
- 3D annotation for multi-slice or spatial review.
- Pixel-level segmentation for masks, contours, and boundaries.
- Multi-slice viewing for findings across adjacent sections.
- Role-based access to restrict data by project and reviewer role.
- Audit logs to track access, edits, exports, and revisions.
- Versioned guidelines to keep reviewers aligned with the current protocol.
- Standardize Annotation Guidelines
Guidelines reduce reviewer variation and keep labels consistent across batches. They should define how labels are assigned, reviewed, escalated, and revised.
A strong guideline includes:
- Label definitions: Each label has a precise clinical meaning.
- Inclusion criteria: Reviewers know when the label applies.
- Exclusion criteria: Similar findings that should not receive the label are defined.
- Reference examples: Positive and negative examples guide consistent decisions.
- Edge-case rules: Borderline cases have defined escalation paths.
- Confidence scoring: Reviewers record uncertainty when evidence is incomplete.
- Adjudication steps: Disputed labels move to clinical review.
- Integrate Compliance into Annotation Workflows
A sound infrastructure is a prerequisite for accessing sensitive health data. Compliance cannot be obtained solely through human observation.
The information environment should have the following features:
- Role-Based Access – Reviewers can only see their assigned data.
- De-identification – Patient Identifiers have been removed or abstracted when possible.
- Encryption – Data is secure both while stored and transferred.
- No Downloads – All local copies and uncontrolled exports are denied.
- Session Monitoring – All reviewer activity is captured.
- Audit Trail – Records of all accesses, edits, exports, and revisions are maintained.
- Retention Controls – Deletion or Archiving of Data is in accordance with institutional policy.
- Conduct Continuous Quality Assurance
Quality assurance (QA) should occur throughout production and not just at completion. Automated QA can identify structural quality issues while the clinical expert can ensure clinical accuracy.
Examples of the items to be reviewed include:
- Consistency of Labels – The same clinical findings should be identified with the same label (i.e., across reviewers and batches).
- Segmentation Accuracy – Masks, polygons, and contours should conform to anatomical landmarks.
- Class Imbalance – Underrepresented cohorts (e.g., rare diseases) must be tracked as explained above.
- Missing Annotations – Reviewers must not miss any required findings, locations, entities, or events.
- Duplicate Labels – Reviewers must delete any recurring or overlapping labels.
- Reviewer Disagreement – Conflicting labels must be resolved by means of clinical adjudication.
- Deviations From Guidelines – Reviewers must follow the most current edition of the guidelines and the most current escalation criteria.
The Strategic Imperative: For most organizations, sustaining the annotation workflows at the clinical depth, secure infrastructure, governance, and review discipline that medical datasets demand is challenging. Specialized data annotation services bring domain experts, medical-grade tools, quality-control frameworks, and scalable human-in-the-loop workflows. Without these capabilities, in-house teams risk slower dataset preparation, inconsistent labeling, greater compliance exposure, and higher operational costs. Outsourcing provides a more cost-effective path to reliable, compliant, and model-ready healthcare AI training data.
The post Data Annotation in Healthcare AI: Key Challenges, Risks, and Best Practices appeared first on The Total Entrepreneurs.
Leave a Reply